AIGC 视频工作流练习

这次练习的重点不是单纯生成一段视频,而是尝试把 AI 视频创作拆成更可控的流程。
AI 视频最容易崩的地方,通常不是“完全做不出来”,而是做出来以后不稳、不准、不受控。人物关系会乱,镜头顺序会跳,动作会变形,Logo 也容易在变形过程中丢掉识别点。问题往往出在一开始就把抽象创意直接交给视频模型,让模型自己猜。
所以这次我把流程拆成两步:先用 Image 2 把创意翻译成视觉方案,再交给 Seedance 2.0 去生成视频。Image 2 更像前期导演和视觉脚本工具,负责把分镜、动作、动画节奏和主视觉想清楚;Seedance 负责把这些已经明确的画面拍出来。
用分镜图控制镜头逻辑
第一个练习是“小猫偷饼干被发现”的短片分镜。我想要的是一个 15 秒左右的喜剧小故事:小橘猫趁主人倒牛奶时靠近饼干,咬下一口后被主人发现,最后假装无辜但嘴边饼干屑暴露了一切。
如果直接把这个故事写成一段文字交给视频模型,它很容易只抓到“小猫、饼干、厨房”这些元素,却忽略喜剧节奏。真正决定短片成立的,是镜头顺序、人物站位、动作方向和最后几秒的停顿。

这张分镜图把故事拆成 9 个镜头,并在同一张画布里加入角色表、场景参考和配色参考。每一格都包含镜头类型、动作、情绪和运动方向。这样后续生成视频时,模型看到的不再是一段抽象故事,而是一张更接近导演脚本的视觉说明。
这一步最有价值的地方,是把“我脑子里的故事”变成“模型能看懂的镜头”。分镜不是为了好看,而是为了减少视频生成时的自由发挥。
用动作表拆复杂运动
第二个练习是青花瓷踢腿动作。舞蹈、武术、转身、跳跃这类动作很容易在 AI 视频里变形,因为它们不是单一姿势,而是一串连续重心变化。
我把实拍动作拆成关键帧:行进准备、左脚踩稳、右腿前踢、屈膝回收、外摆、转身、腾空、定格。每个姿态都标出大概时间点和身体状态,让模型先理解动作路径,再进入视频生成。

这一段让我意识到,复杂动作不能只靠一句“完成一个踢腿动作”。更稳定的方法是先做动作表,把连续运动拆成关键姿态。视频模型需要的不是形容词,而是可执行的时间线。
用动画表控制 Logo 变形
第三个练习是 HBG Logo 动画。Logo 出场动画看起来简单,但其实很容易失控:一旦变形过程过长,模型就会把 Logo 画成另一个东西;如果只说“光点变成椰树 Logo”,中间过程也会很随机。
我先做出最终 Logo,确定黑底、发光线条、椰树符号和 HBG 字标的关系。
![]()
然后把动画拆成 6 个阶段:光点出现、能量聚拢、椰子轮廓、芽生长、椰树定型、字标显现。动画表里还标注了每一段的时间、缓动方式和形态注意点。
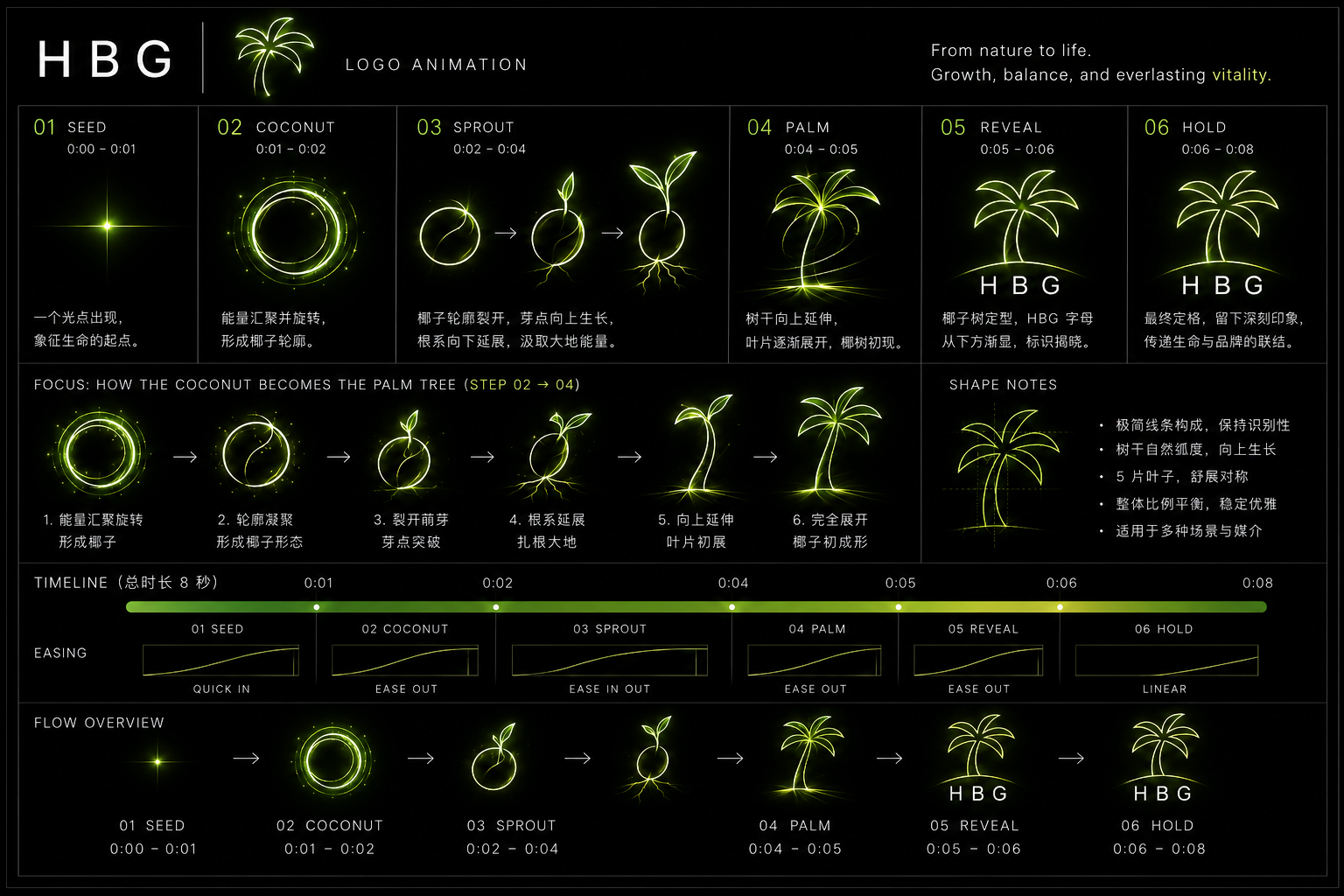
这类品牌动画不适合让模型自由发挥。步骤越少、背景越干净、变形描述越具体,最终 Logo 越容易稳定。这里真正要控制的是“从哪里来、怎样变、最后停在哪里”。
用主视觉定住 MV 氛围
最后一个练习是情绪向 MV Demo。MV 不只是把人物放进舞台,而是要有统一的角色符号、场景氛围和摄影方式。
我用“带天使翅膀和光环的女子,在小型现场演出场所弹吉他”作为主视觉方向,并把画面控制在阴郁逆光、观众剪影、舞台近景和吉他细节之间。Image 2 先生成一张完整的镜头参考图,再交给 Seedance 生成视频;后续用 Suno 做音乐,用剪映调节节奏和字幕,快速拼成一个示例 Demo。
主视频放在页面开头。它不是一个完整 MV 成片,更像一次流程验证:先用主视觉锁定情绪和摄影语言,再让视频模型补足镜头推进。
复盘
这次练习让我更清楚地看到,AI 视频的关键不只是提示词写得漂亮,而是能不能把创意先翻译成模型能执行的视觉方案。
对我来说,这套流程可以总结成四步:
- 用分镜图控制镜头顺序和叙事节奏。
- 用动作表拆解复杂运动,减少姿态变形。
- 用动画表控制 Logo 或图形的变形过程。
- 用主视觉锁定角色、符号、场景和摄影方式。
Image 2 负责把视频想清楚,Seedance 负责把画面拍出来。前期视觉方案越明确,后期生成就越不像碰运气。
输出信息
- MV Demo: 14.43 seconds, 1920 x 1080
- Logo animation: 8.06 seconds, 960 x 960
- Action demo: 5.47 seconds, 1080 x 1920
- Focus: storyboard, action sheet, animation sheet, visual direction
- Tools: Image 2, Seedance 2.0, Suno, 剪映