跨境电商五级考前训练舱
这是一个从真实复习痛点里长出来的学习工具。参加跨境电商培训班时,学校系统里有一套完整题库,但页面里的内容不方便复制、检索和复盘;考试越近,找题、整理错题、判断重点都会不断消耗注意力。
我先把原始题库整理成可用数据,再做拼音检索站 py.karry.asia 解决“临时查题”的问题。后来发现查题只能应急,真正复习时还需要连续练习、错题回看和重点筛选,于是继续做成刷题项目 ks.karry.asia。这两个站点的关系也很清楚:一个负责快速定位题目,一个负责把题目变成训练过程。
项目目标
这个项目不是从“做一个产品”开始的,而是从一个具体麻烦开始的:题在那里,但不好用。
我希望它先解决三件具体的事:
- 把无法顺手整理的学校题库变成可检索、可训练的数据。
- 让不同复习节奏的同学都能找到合适入口。
- 在不增加登录负担的前提下,沉淀集体错题和收藏信号。
从题库到训练
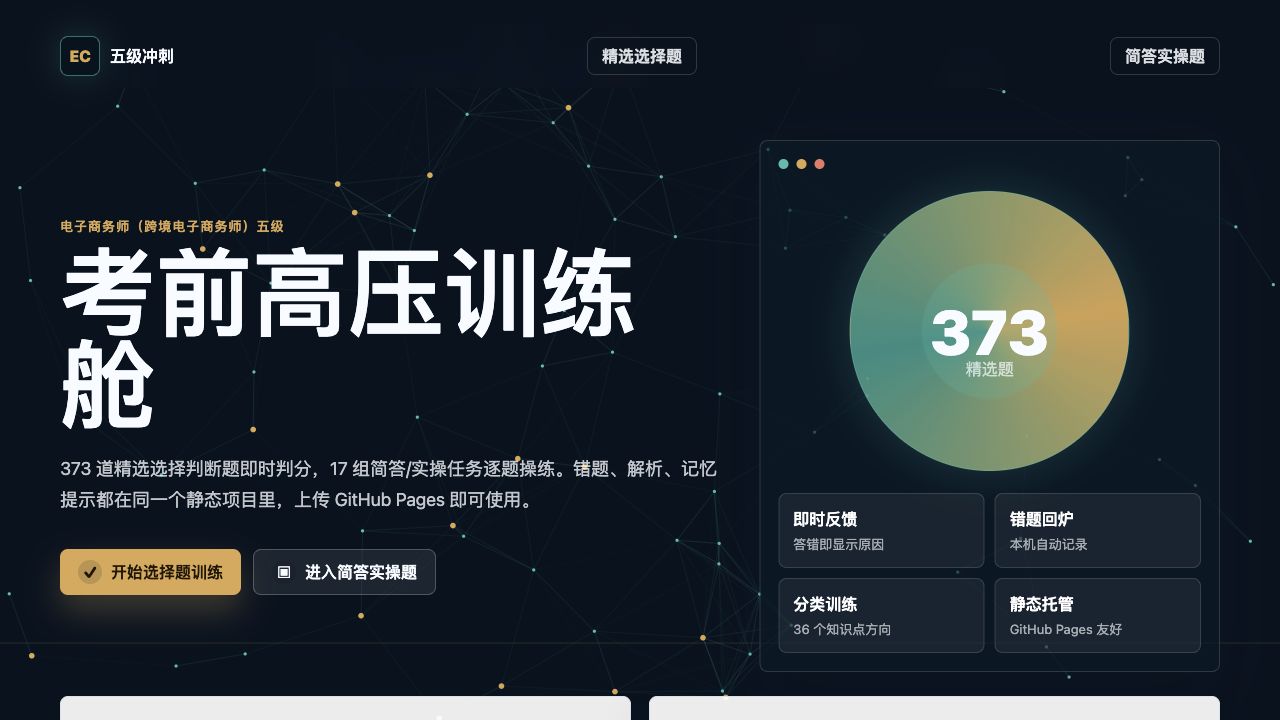
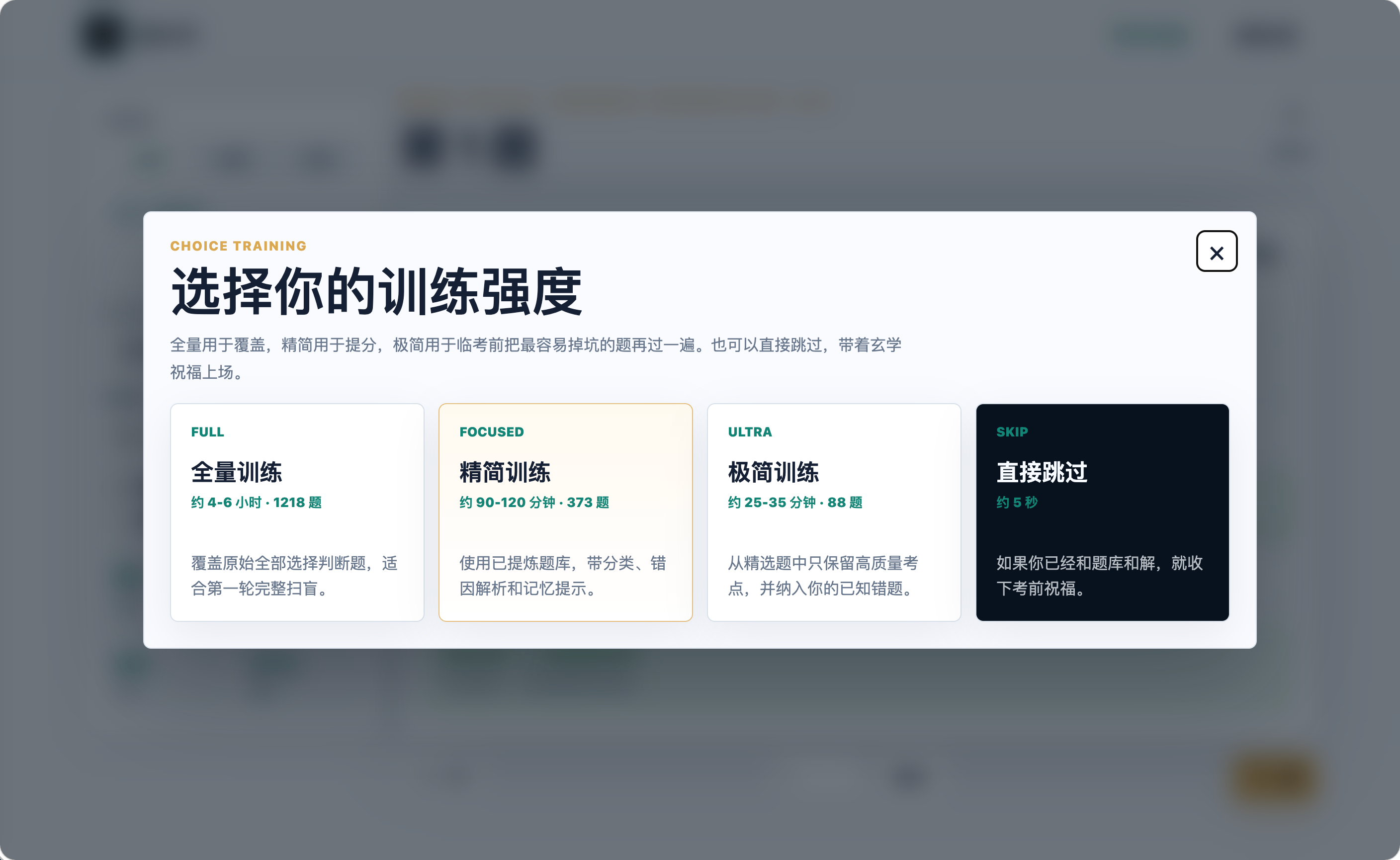
原始题库共有 1218 道选择判断题。直接全量刷题会有覆盖感,但也容易在临考前带来压力,所以我把题库分成了三层训练入口:
- 全量训练:1218 道原始选择判断题,适合第一轮扫盲。
- 精简训练:373 道重点题,适合集中提分。
- 极简训练:88 道高价值题,适合临考前快速过重点。
题库整理过程中,我用多智能体协作完成格式清洗、答案校验、重复题筛选、错因解析和记忆提示补充。原始数据里还清理出 532 条可疑 E 选项。这里没有完全相信模型输出,每一轮精简后都要回看原题,避免把“看起来重复”的题误删掉,因为有些题只是选项顺序相似,考点其实不同。
核心体验
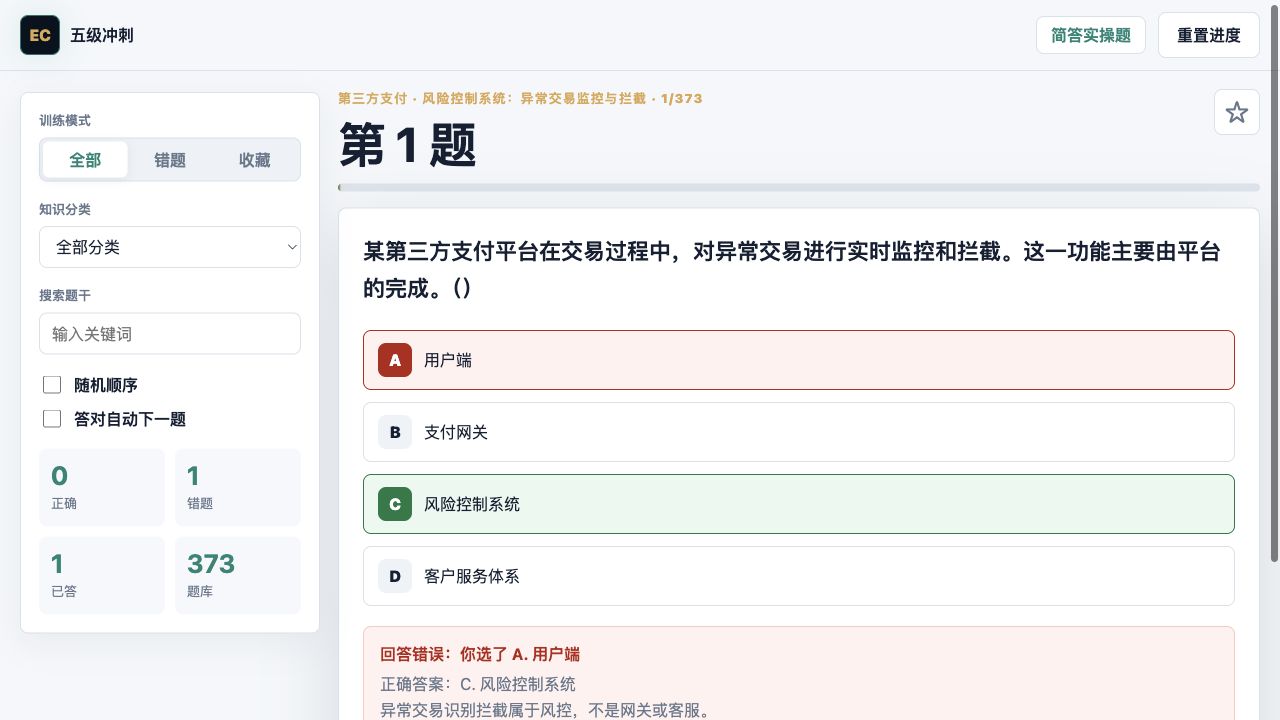
刷题页围绕“快速做题、及时知道原因、方便回头复盘”来设计。用户答题后可以立即看到正确答案、自己的选择、解析和记忆提示;错题、收藏和训练进度会保存在本地,适合反复练习。
页面还保留了简答/实操题入口,让选择题训练和主观题复习可以放在同一个项目里完成。
实际使用后,同学反馈最有用的不是“功能多”,而是可以在考前直接切到 88 道极简题,快速确认自己还会不会错。这个反馈也让我把入口做得更明确:复习后期比起展示完整题库,更需要减少选择成本。
匿名统计
一开始项目是纯静态页面,优点是简单、便宜、打开就能用;但它只能保存每个人自己浏览器里的进度,无法沉淀“大家普遍错在哪些题”。
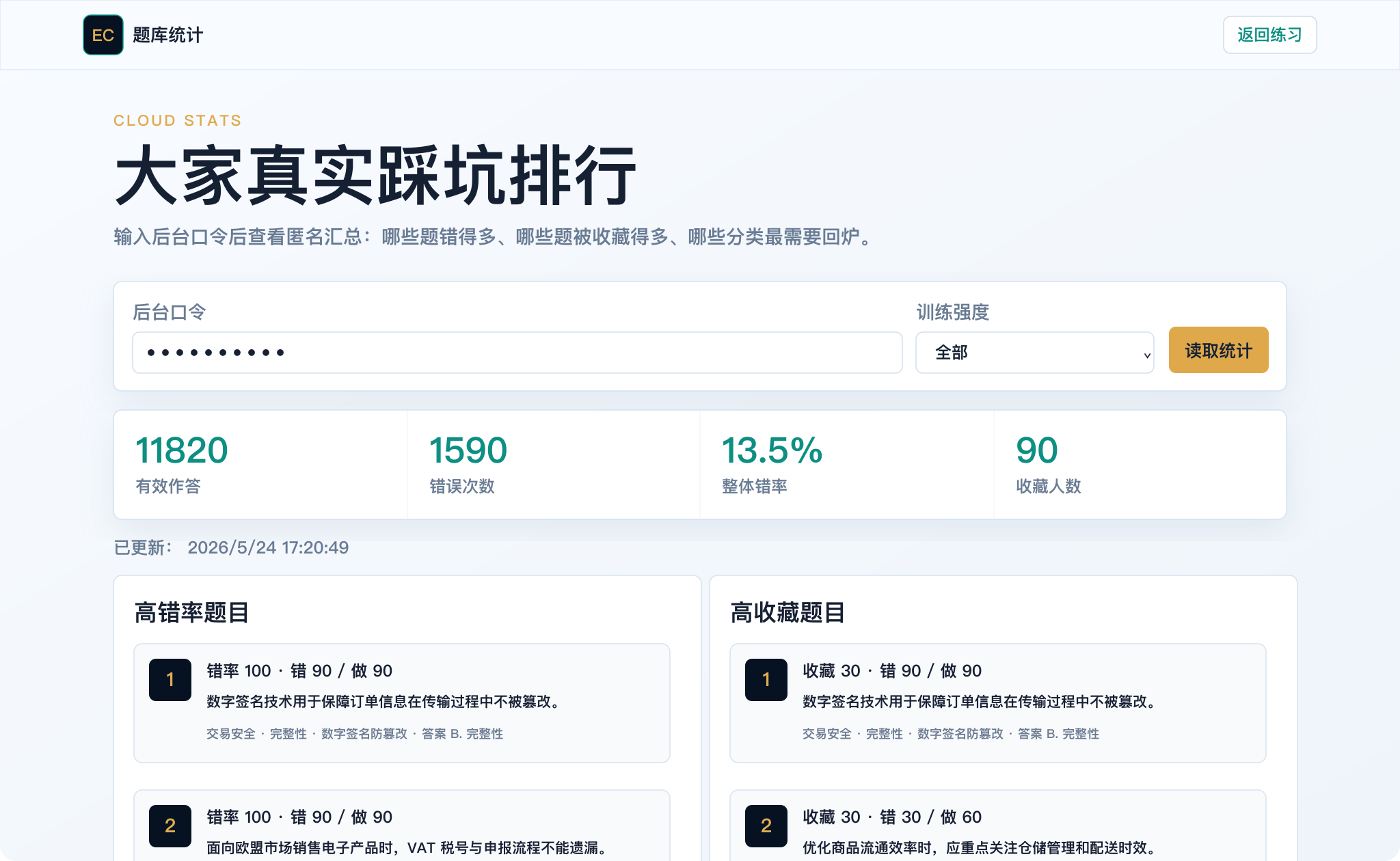
后来我加了一层轻量后端:用 Cloudflare Pages Functions 和 D1 数据库记录匿名作答与收藏数据。这里的取舍是放弃个人账号体系,不做排名和用户画像,只按题目维度统计。这样数据不够“精细”,但部署简单、访问门槛低,也更适合一个临考工具。
后台可以查看高错率题、收藏排行和分类概览;前台用户则能看到每道题的全站收藏数。这样,一个人踩过的坑可以变成后来者复习时的重点信号。
迭代与回滚
这个项目中间回滚过几次。训练强度入口最早放在答题卡上方,后来发现它抢走了做题注意力,于是改成侧边栏按钮加弹窗。极简题库也曾尝试改写选项来降低猜题空间,但效果不自然,最后撤回,重新回到题目质量本身。
还有一个隐蔽问题来自不同训练模式之间的进度映射。用户可能先在 373 道精简题里练习,再切到 88 道极简题;如果只按当前题号记录,统计和错题导出都会错位。后来我统一用原始题目的 source_id 关联,再按当前训练模式显示统计,才把进度逻辑理顺。
我的收获
这个项目真正想展示的不是某个单独功能,而是一条完整执行链:从真实场景发现问题,把不可用的内容整理成数据,先做拼音搜索解决查题,再做刷题工具解决练习和复盘,最后根据同学反馈继续调整。
这次收获更偏执行层面:先做查题站,把数据整理通;再做刷题站,把练习闭环跑通;最后才补匿名统计,判断哪些题值得优先复盘。它不是一次从零到完整产品的规划,而是在真实复习压力里一层层补出来的。
产出内容
- 拼音检索项目 py.karry.asia
- 在线刷题项目 ks.karry.asia
- 1218 道原始题库结构化整理
- 373 道精简训练题与 88 道极简重点题
- 即时反馈、错题记录、收藏重点、简答题入口
- 匿名作答统计、收藏数、高错率题后台
- GitHub 仓库:karry1155/cross-border-exam-practice